When an API Layer Beats a Full Rewrite for Legacy Operations

A full rewrite often sounds cleaner than the reality it creates.
Leadership wants speed. Product teams want fewer workarounds. Operations wants fewer outages and less duplicate entry. Engineering wants an architecture that is easier to change.
Those are valid goals. But a full replacement is not automatically the shortest path to them.
In many business-critical environments, the better first move is to create a controlled interface around the old system so new apps, workflows, and services stop depending on brittle direct connections. That is where an API layer or facade can be far more valuable than a rewrite-first mindset.
Direct answer
An API layer usually beats a full rewrite when the business still depends on the legacy system's core rules and data, but current integrations are slow, fragile, or hard to extend. The wrapper gives the team a cleaner contract for new channels and staged modernization, while protecting continuity until the riskiest domains can be replaced deliberately.
If the old system is fundamentally unsafe, impossible to understand, or too unstable to expose reliably, the answer may still be faster domain replacement. But many organisations are not dealing with total collapse. They are dealing with an awkward middle state where continuity matters more than architectural purity.
Why rewrite-first decisions go wrong
Full rewrites often begin with a true complaint and end with the wrong sequencing.
The complaint is usually real:
- changes are slow
- integrations are brittle
- reporting is inconsistent
- mobile or web channels depend on awkward legacy logic
- every new feature requires too many exceptions
The mistake is assuming the whole system must be replaced before any of those problems can improve.
In business-critical operations, rewrite-first can create three risks at once:
1. Continuity risk
The old platform may still run booking, billing, service records, entitlement rules, inventory logic, or approval flows that the business cannot afford to interrupt.
2. Scope risk
Once a replacement programme starts, teams often discover that the system carried more hidden rules and edge cases than anyone documented. Scope expands, timelines stretch, and pressure rises.
3. Coordination risk
A replacement frequently forces frontend, backend, data, reporting, integrations, training, and support change to move at the same speed. That is rarely how the business actually works.
This is why the staging logic in Martin Fowler's Strangler Fig Application pattern remains useful. AWS's guidance on the strangler fig pattern makes the same point in cloud-modernisation terms: isolate, redirect, replace in stages, and reduce risk through controlled transition rather than one giant cutover.
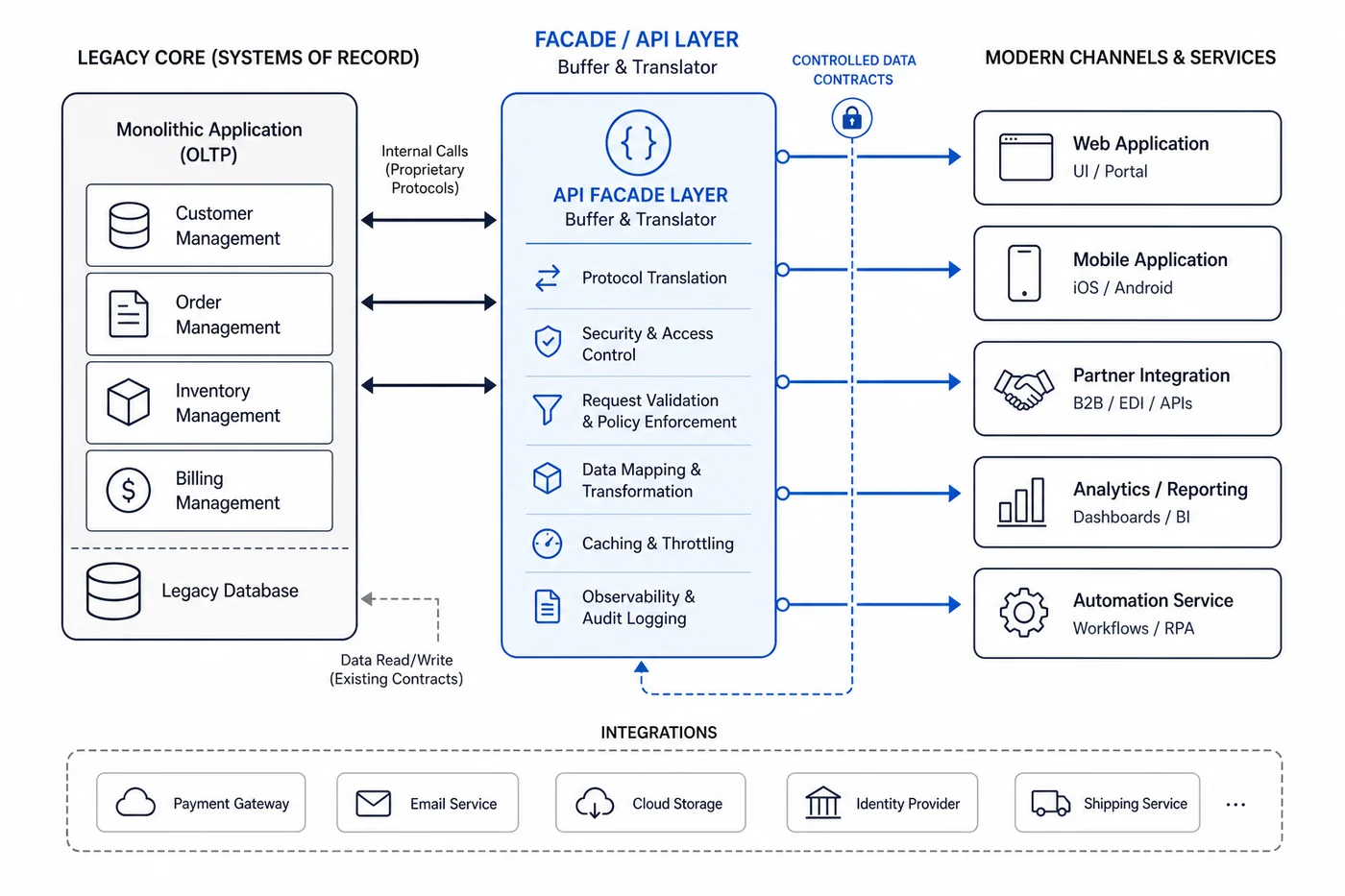
What an API layer actually does
An API layer is not a cosmetic wrapper. Used well, it changes the shape of modernisation.
It creates a stable, governed interface between the legacy core and the newer channels or services around it.
That can help in several ways.
It reduces direct dependency sprawl
Without a proper interface layer, every new app, partner integration, workflow tool, or report pipeline may connect differently to the old platform.
That multiplies fragility. One schema change or workflow workaround ripples everywhere.
A facade gives the business a cleaner contract. New consumers talk to the controlled layer instead of coupling themselves directly to the legacy internals.
It lets the team modernise in slices
Not every domain is equally urgent.
One business may need to modernise customer self-service first. Another may need better service scheduling. Another may need mobile field reporting without changing billing rules immediately.
An API layer can separate those concerns enough that new experiences can move faster while the team protects the old system's stable responsibilities.
It improves observability and control
A transition layer can centralise authentication, validation, transformation, rate handling, and logging in ways the legacy platform often cannot.
That makes the system easier to monitor and safer to extend.
It buys time for better replacement decisions
The biggest advantage is strategic. Once the business is no longer forced to hit the legacy core in ten different ad hoc ways, it becomes easier to decide what should be replaced first and what should simply be stabilised.
That is exactly the kind of sequencing logic that sits behind legacy system migration planning for critical operations.
Where an API layer helps most
An interface-first path is often strong when the organisation faces one of these conditions.
Multiple new channels need the same old data or rules
This is common when a business wants a new mobile app, portal, partner integration, or reporting flow while the old system still owns the source of truth.
In those cases, exposing a stable service contract can unblock delivery without forcing the entire core to be rebuilt first.
The legacy system still contains valuable business logic
Many old systems are not useless. They are awkward.
They may still encode pricing rules, entitlement rules, operational approvals, or edge-case handling that took years to accumulate. Throwing all of that away at once creates rediscovery risk.
The current pain is at the edges, not only the centre
If the worst pain comes from data exchange, frontend constraints, or slow partner integration rather than complete core failure, a wrapper can generate value quickly.
The organisation needs continuity while it learns
A staged interface gives teams room to modernise with evidence rather than assumption. That is especially important when the business is still learning which domains actually deserve replacement first.

When wrapper first beats rewrite first
A wrapper-first path is usually stronger when most of these statements are true:
- the legacy core still runs essential business rules reliably enough
- the business needs new channels or integrations soon
- direct point-to-point connections are already messy
- replacement scope is still unclear
- the organisation cannot pause roadmap delivery for a massive rebuild
- the team needs better visibility before choosing which domain to replace first
A rewrite-first path is more justified when most of these statements are true:
- the old system is unsafe or operationally unstable
- core rules cannot be trusted or understood
- data quality is too poor to expose safely
- change is impossible even with a controlled facade
- the business is already prepared to replace a clearly bounded critical domain quickly
That difference is similar to the judgement behind mobile app rewrite vs mobile app modernization. The best choice depends less on whether the system feels old and more on where the real delivery constraint sits.
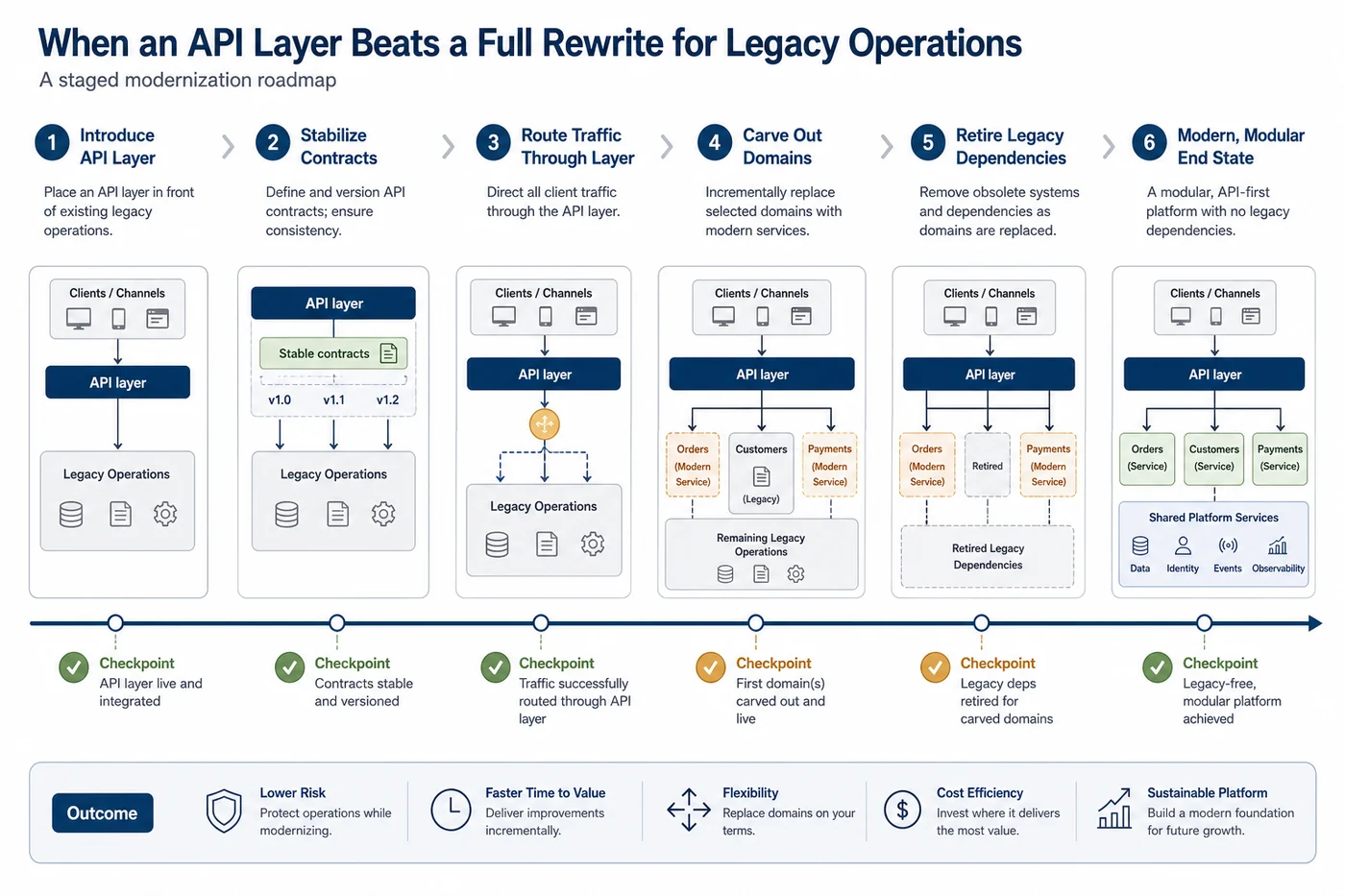
A staged modernization sequence that works better
A practical interface-first programme often looks like this.
Stage 1: map the contracts that matter
Identify the data and behaviour that downstream teams actually need:
- customer profile reads
- order or booking status
- job updates
- billing events
- service history
- access or entitlement checks
Do not expose everything. Expose the high-value contracts first.
Stage 2: stabilise the boundary
Create the facade with validation, logging, transformation rules, and ownership. The goal is not only access. The goal is controlled access.
Stage 3: route new work through the layer
New portals, mobile channels, or integrations should use the controlled interface instead of creating another custom direct dependency.
This is where adjacent work such as mobile app development benefits. The mobile experience can improve while the core is modernised in stages behind the scenes.
Stage 4: carve out replaceable domains
Once the boundary is cleaner, the team can replace specific domains deliberately:
- notifications
- reporting pipeline
- scheduling service
- customer self-service modules
- selected master-data domains
Stage 5: retire the old paths
As new domains become trustworthy, old direct connections and obsolete logic can be switched off progressively instead of all at once.
The risks of doing the wrapper badly
An API layer is not automatically the right answer. It can become a new mess if used without discipline.
Risk 1: the wrapper becomes a permanent dumping ground
If every exception, workaround, and business rule is thrown into the facade without ownership, you simply create a second legacy layer.
Risk 2: no domain plan follows the interface work
A wrapper should support staged modernisation, not replace the need for prioritisation.
Risk 3: the team exposes unstable internals directly
If the facade mirrors the legacy chaos instead of cleaning it, downstream teams still inherit the same risk in a prettier format.
Risk 4: success is measured only in technical terms
The real measure is business change: faster releases, lower integration risk, fewer duplicated interfaces, safer channel expansion, and clearer migration choices.
What buyers should really ask before approving a rewrite
Before approving a large replacement programme, ask:
- what business capability must improve first?
- what currently depends too tightly on the old system?
- which interfaces create the most drag or risk today?
- what can be stabilised before it is replaced?
- which domain genuinely deserves full rebuild priority?
If those questions do not have clear answers yet, an interface-first move often creates the clarity the programme still lacks.
That is why Virtualspirit treats this as a sequencing decision, not a doctrine. The right modernisation path is the one that reduces operational risk while improving delivery options, not the one that sounds most dramatic in architecture discussions.
FAQ
When is an API layer better than a full rewrite?
It is usually better when the business needs continuity, the core system still contains valuable rules or data, and the main pain comes from rigid integration points rather than total platform collapse.
What does an API layer actually change?
It creates a cleaner interface around the legacy system so new channels, apps, or workflows can connect in a more controlled way while the organisation modernises in stages.
Can an API layer become technical debt?
Yes. It becomes technical debt if the team uses it as a permanent hiding place for poor ownership, bad data, or unlimited custom exceptions instead of as a governed transition layer.
Should every legacy system be wrapped before replacement?
No. If the core platform is too unstable, too insecure, or too opaque to expose safely, the better answer may be faster replacement of the riskiest domain rather than a wrapper-first path.
CTA: Modernise the boundary before you replace the core blindly
A full rewrite is not a strategy by itself. The real strategy is choosing the transition path that protects continuity while giving the business room to improve.
- Primary CTA: If you need help deciding whether to wrap, split, or replace a legacy platform, talk to Virtualspirit about a modernization readiness assessment through bespoke development.
- Secondary CTA: Before committing to a big rebuild, review the checklist in legacy system migration planning for critical operations and map where continuity risk actually sits.



