AI Readiness Audit Checklist for Mid-Sized Teams Before Your Production Rollout


Most mid-sized teams do not get into trouble with AI because the model is useless. They get into trouble because a promising pilot is pushed toward launch before the live operating conditions are ready.
That makes this article different from a pre-scope checklist or a general AI strategy conversation. At this stage, you already have a candidate workflow, a working concept, or even a successful pilot. The question is narrower and more serious: is this specific workflow actually safe and supportable enough to go live?
Direct answer
Before you move AI into production, run a go-live audit across six launch gates: live workflow fit, production-grade input discipline, human review and escalation rules, integration cutover readiness, security and operating controls, and post-launch monitoring with rollback ownership. If any one of those is still vague, the rollout is early. If all six are explicit, owned, and testable, the team can move from pilot confidence to controlled production release.
That is the practical line between a pilot that impresses stakeholders and a workflow the business can trust on a busy week.
If you need a narrower operator-facing next step after this audit, the AI Deployment Readiness Assessment page shows how Virtualspirit scopes rollout ownership, fallback design, QA, and go-live guardrails before production.
Why this audit is a launch decision, not a planning exercise
A lot of AI content talks about use-case discovery, roadmap planning, or whether a workflow is worth scoping. Those are valid questions, but they are not the same as a production audit.
A production audit starts later.
At that point, the team usually already believes the workflow is valuable. A pilot has shown promise. Business users can see the upside. Engineering can imagine the architecture. Leadership wants to know what it would take to launch.
That is exactly where teams become vulnerable.
The conversation shifts too quickly from “this looks useful” to “let’s roll it out.” Then the uncomfortable operational questions appear:
- Can the live input stream support this every day, not just in curated tests?
- Do operators know when to approve, override, or stop the workflow?
- Can the surrounding systems absorb the new step without hidden manual bridging?
- Does anyone own the first week of production support?
- What happens when quality drops or an integration goes down?
Those are launch questions, not innovation questions.
If your team still needs help deciding whether a workflow is mature enough to estimate in the first place, the better starting point is a workflow-specific readiness piece like AI Workflow Readiness Checklist: What Must Be True Before You Scope the Build. If your problem is that the pilot already exists and you need a hard go-live decision, this audit is the right frame.
The six-part AI readiness audit

1. Live workflow fit: are you launching a bounded operational step, not a vague ambition?
A production rollout should attach to one bounded workflow with a clear trigger, input set, output, approver, and system of record.
That sounds basic, but many teams still try to launch something too broad, such as:
- “use AI in support”
- “automate our operations workflow”
- “add a copilot for internal teams”
Those are portfolio themes, not production units.
A launchable workflow sounds more like this:
- classify inbound support tickets and draft replies for tier-one review
- extract supplier invoice fields and route exceptions to finance approval
- summarise sales call notes into CRM fields before manager sign-off
If the workflow is still too broad, your launch plan will hide risk inside edge cases and undefined handoffs.
A go-live audit should confirm:
- the exact production trigger
- the production input objects
- the expected output state
- the human checkpoint, if any
- the system where the final approved result is stored
If those are still moving, the team is not auditing launch readiness yet. It is still shaping scope.
2. Production-grade input discipline: are the live inputs reliable enough to trust the output?
Pilots often survive on human cleanup. Someone fixes bad formatting. Someone pastes missing context into the prompt. Someone manually skips the worst cases before the model sees them.
Production does not forgive that kind of hidden help.
Your audit should examine the real input conditions the workflow will face after launch:
- where the data comes from
- which fields are required
- what percentage arrives incomplete or malformed
- whether records are duplicated or delayed
- whether the workflow depends on PDFs, spreadsheets, screenshots, and chat messages mixed together
- who owns input quality when upstream conditions change
This matters because the business will judge the rollout by the live result, not by the pilot’s best-case path.
Mid-sized teams often underestimate this because the model appears capable in a controlled environment. In reality, input discipline is usually the bigger limiter than model quality.
The audit should leave the team with a plain-language answer to one question: what does a “good enough” production input look like, and what happens when it is not present?
If nobody can answer that, the launch is early.
3. Human review and escalation: who approves what, and what happens when confidence is low?
This is where a lot of launches become unsafe.
A useful pilot can make people feel that the workflow is “basically done.” In production, that is rarely true. Most first releases should make human review faster and more consistent, not pretend the need for review has vanished.
Your audit should define:
- which outputs are suggestions only
- which outputs can auto-route but not auto-decide
- which outputs, if any, can be executed automatically
- what confidence or business rule sends work to human review
- who owns the approval queue
- what escalations are triggered by risky, incomplete, or conflicting output
For most mid-sized teams, the safest first production pattern is still human-in-the-loop.
That is not a weakness. It is a sign that the team understands how trust is earned in live operations.
If the current plan still sounds like “the AI will mostly know what to do,” the audit has not gone deep enough.
4. Integration cutover readiness: can the workflow live inside the current stack without heroic workarounds?
A surprising number of AI workflows look ready until they touch the real systems around them.
The live workflow may need to read from a CRM, attach to a ticket, call an internal API, update a queue, trigger an approval step, or write back into a legacy platform that was never designed for elegant machine-to-machine handoffs.
This is where many teams discover that their “AI problem” is partly an application architecture problem.
A launch audit should check:
- which systems are in scope on day one
- whether the required APIs or exports are stable enough for production
- which permissions, audit trails, and access boundaries apply
- what happens when one dependency is unavailable
- whether the workflow can degrade gracefully instead of silently failing
- whether an adapter or API layer is needed before broader rollout
This is exactly why many mid-sized teams benefit from an interface-led approach instead of a rushed rewrite. As we covered in When an API Layer Beats a Full Rewrite for Legacy Operations, a controlled integration layer often creates a safer launch path than trying to modernise everything at once.
If the AI workflow still depends on someone manually bridging systems behind the scenes, it is not production-ready. It is still a prototype wrapped around integration debt.
5. Security and operating controls: what can go wrong when this runs live?
Security and governance are often postponed because they feel slower than experimentation. In reality, they are what separate a pilot from a business system.
The audit should cover at least these questions:
- what data the model is allowed to access
- what data must stay inside a controlled boundary
- whether prompts, outputs, and approvals are logged appropriately
- whether role-based permissions are defined
- what policy applies if the output conflicts with business rules
- how the workflow is disabled or tightened if behaviour degrades
- who signs off on production risk
For LLM-based workflows, these are practical concerns, not abstract policy topics. Prompt injection, insecure outputs, excessive action authority, and weak auditability all become production problems very quickly once the workflow touches customers, revenue, compliance, or internal approvals.
NIST’s AI Risk Management Framework is useful here because it treats governance as something operational: map the risk, define controls, measure behaviour, and manage it continuously.
A founder or operator should insist on plain-language answers. If the team cannot explain how access, approval, and incident handling work, the launch is not ready for governance review.
6. Post-launch monitoring and rollback ownership: how will you know the workflow is still healthy next month?
Production AI must be observable.
Anecdotes are not enough. “It seems faster” and “users like it” are useful signals, but they are not operating evidence.
Before launch, the audit should define:
- what success looks like
- what failure looks like
- which metrics indicate drift or degradation
- who reviews those metrics
- how often outputs are sampled or audited
- what thresholds trigger rollback, tighter review, or expansion
Useful production signals usually include a mix of quality, throughput, and control metrics, such as:
- turnaround time before and after rollout
- percentage of cases needing human correction
- frequency of missing critical fields
- exception rate by workflow type
- failed integrations or retries
- approval turnaround time
- operator override rate
Google Cloud’s MLOps guidance is relevant here because it reinforces the same operational lesson: production systems need validation, lineage, monitoring, and rollback discipline.
If those measures do not exist before launch, the team will struggle to make confident decisions once the workflow is live.
What usually makes a team fail this audit
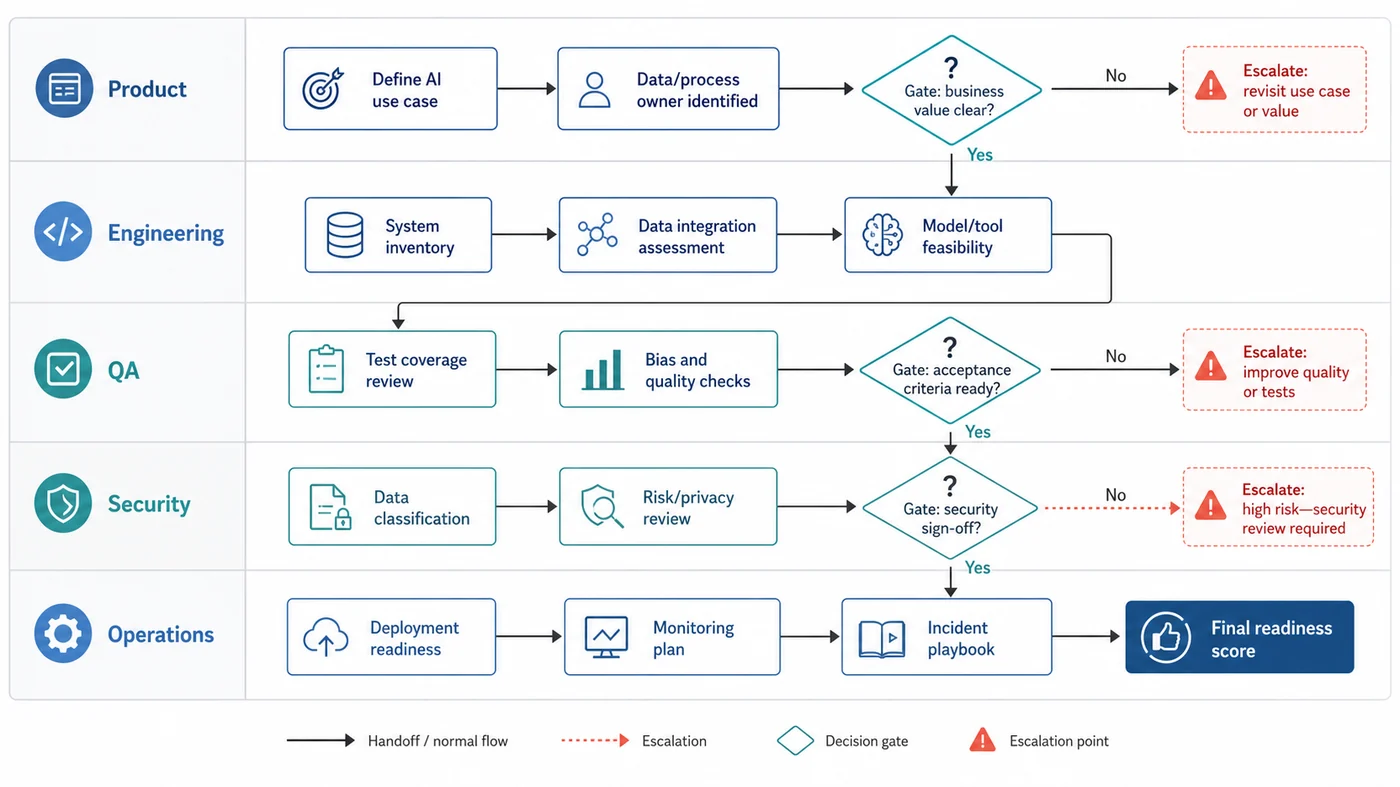
The biggest blocker is rarely the model itself. It is hidden fragility.
The pilot only works with expert babysitting
If one smart person is quietly fixing inputs, screening bad output, or adding missing context before the rest of the team sees the result, that is not launch readiness. That is human scaffolding around a useful experiment.
Ownership is still split across too many people
If nobody can explain who owns the business outcome, who owns the technical workflow, and who owns the first-line support response, the team has not built a production operating model.
Exceptions are frequent but undocumented
When teams say, “we’ll just handle those manually,” they often mean they have not yet turned recurring exceptions into workflow rules. If the edge cases happen every week, they are part of the design.
Integration success depends on fragile workarounds
Manual exports, copied data, hidden spreadsheets, or informal approval loops are all signs that the production path is not stable enough yet.
No one has defined what stays manual in release one
A good first rollout is explicit about what is still out of scope. Clear non-automation boundaries are often what make the first release commercially safe.
A practical rollout sequence for mid-sized teams
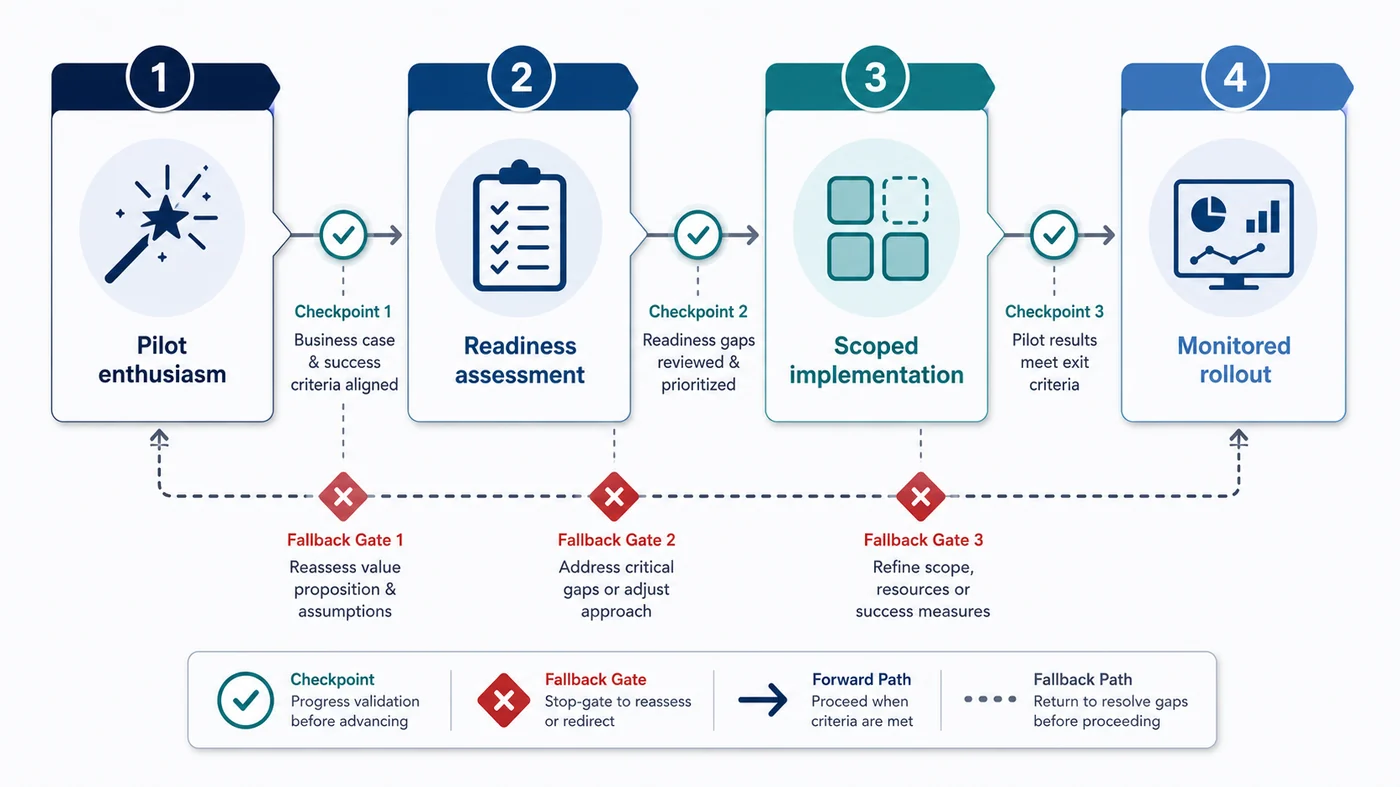
Most mid-sized teams do not need a dramatic AI transformation programme to launch responsibly. They need a disciplined go-live order.
A practical sequence looks like this:
- Audit the workflow for pain, repeatability, input quality, exception patterns, and ownership.
- Define the bounded production release instead of trying to automate the whole lane.
- Set review and escalation rules in plain language.
- Stabilise the integration path so launch does not depend on hidden manual bridging.
- Test failure paths and business logic before wider release.
- Launch with monitoring and rollback ownership already assigned.
That fifth and sixth step are where many rushed rollouts fail. Production AI does not only need model evaluation. It needs workflow validation, regression checks, integration testing, and confidence that surrounding systems will not quietly break the automation later.
That is why support capabilities like AI automated software testing belong in the same conversation. If the workflow is not testable, the launch is harder to trust as the system evolves. For a delivery example of workflow automation where structured processing and operational reliability matter, see the Claims App case study.
When to move ahead, and when to hold launch
Move ahead when the workflow is bounded, the inputs are dependable enough, the approval model is explicit, the integration path is understood, the production owner is named, and the team knows how it will monitor and support the release.
Hold launch when the plan still depends on assumptions like these:
- “We’ll clean the data after go-live.”
- “Operators will know when the output looks wrong.”
- “We can stabilise the legacy integration later.”
- “We don’t expect many unusual cases.”
- “We’ll decide the operating metrics once it is live.”
Those are not rollout plans. They are deferred risks.
The commercial question behind the audit
A proper readiness audit is not red tape. It is how a mid-sized team avoids buying speed at the cost of control.
Good operators do not ask only whether AI can be useful in theory. They ask whether this workflow, with these systems, this team, and these controls, is ready for live use now.
That is also the point where outside architecture support becomes commercially valuable. An experienced implementation partner should be able to tell you three things quickly:
- what is ready for production now
- what needs cleanup first
- what should stay in pilot scope until the workflow or integration design improves
If you want that view before committing launch effort, Request AI Readiness Assessment through the AI integration and infrastructure service. If you already have a pilot and mainly need a firm opinion on controls, cutover order, and go-live risk, Talk to AI Architect.



