Why AI Pilots Stall Before Production: 7 Readiness Gaps Mid-Sized Teams Must Fix First


AI pilots usually do not die because the idea was bad. They stall because the organisation treated production as a later problem.
Direct answer
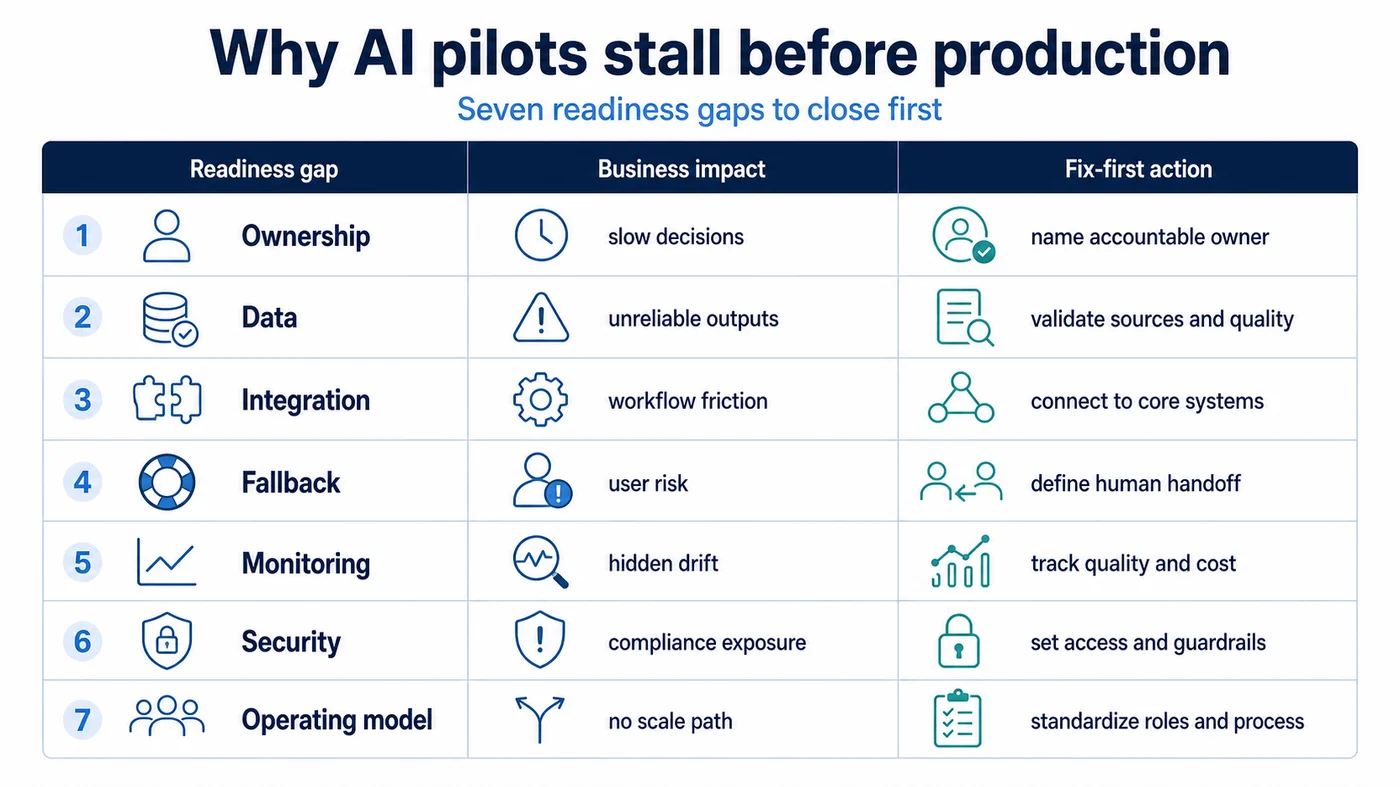
If your AI pilot looks promising but keeps stopping short of rollout, the issue is usually not “more prompting” or “a better model.” It is production readiness. Mid-sized teams need seven things in place before AI can run safely inside live operations: clear ownership, dependable data, integration discipline, fallback paths, monitoring, security controls, and a practical operating model. Without those, the pilot stays stuck as a demo, side experiment, or expensive exception process.
That is exactly where AI integration and infrastructure work matters. The value is not just getting a model to respond. The value is diagnosing what prevents the business from trusting the workflow enough to launch it.
A lot of teams recognise the use case before they recognise the delivery problem. They can see where AI might reduce repetitive work, improve service speed, or help staff make better decisions. But once they try to connect that pilot to real systems, real approvals, and real risk, progress slows down fast.
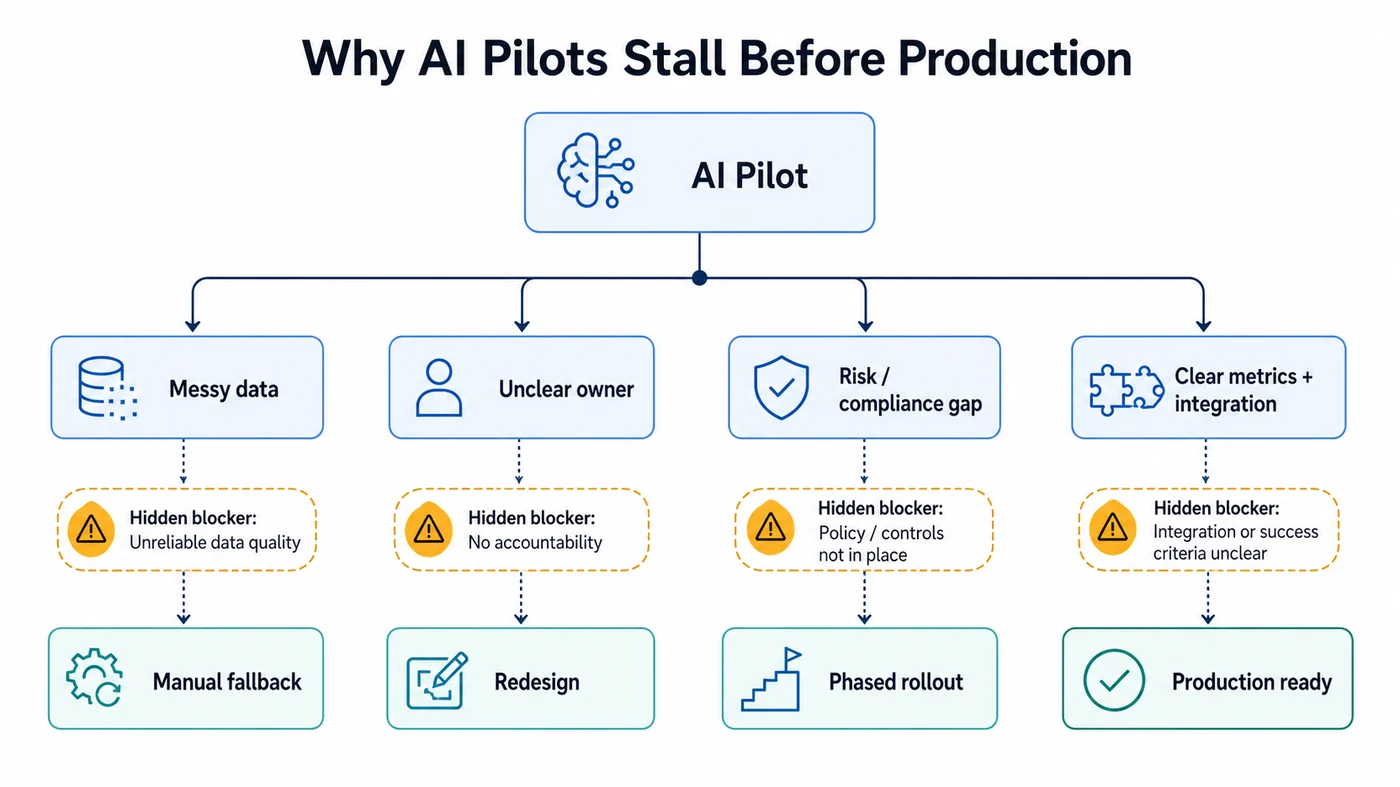
In our experience, that slowdown is not random. The same seven readiness gaps show up again and again.
1. No one owns the production outcome end to end
Many pilots start inside one function. Operations wants faster case handling. Sales wants better qualification. Customer support wants faster replies. IT enables the experiment, but no one is clearly accountable for the live system after the pilot.
That creates a dangerous gap. The business owner thinks technology will “take it from here.” The delivery team thinks the business will define policy and acceptance. Security expects someone else to handle risk. Nobody owns the complete answer.
In production, AI needs a named owner for the outcome, not just the tool. Someone has to decide what success looks like, what the acceptable error rate is, when humans must step in, and what should happen when the system behaves unexpectedly.
This is why governance cannot be saved for later. The NIST AI Risk Management Framework is useful here because it treats AI risk management as an ongoing organisational discipline, not a one-off technical checklist. The point is simple: if ownership is vague, the rollout will stay vague too.
What to fix first: assign one commercial owner and one technical owner, and make them jointly responsible for launch readiness, operating rules, and post-launch decisions.
2. The pilot works on sample data, not business-grade data
A pilot often looks strong because the inputs are cleaner than reality. The team tests with known documents, selected records, or a narrow process slice. Then production introduces exceptions, missing fields, inconsistent naming, duplicate records, and timing issues from upstream systems.
That is where confidence drops. The model might still be capable, but the workflow becomes unreliable because the inputs are unreliable.
Mid-sized companies feel this more sharply because data responsibilities are often spread across several teams and older systems. You may not need a full platform rebuild, but you do need to know which systems are authoritative, where the handoffs break, and what data quality rules must be enforced before AI gets involved.
If the pilot depends on customer, product, or transaction records moving across old systems, it is worth reviewing your data movement assumptions early. That is also where related support work like data migration planning becomes part of AI readiness, not a separate future project.
Google’s MLOps guidance is useful on this point because it stresses data validation and model validation as production pipeline requirements, not optional cleanup. If schema skews or significant data changes can break the flow, the system needs a rule for stopping, escalating, or retraining rather than quietly producing bad output.
What to fix first: define your required input fields, detect bad or missing data before inference, and document which team owns each upstream source.
3. Integration is treated like plumbing, when it is actually the hard part
This is where many good pilots get stranded.
The demo works in a notebook, an isolated app, or a vendor sandbox. But the live business process depends on ERPs, CRMs, ticketing systems, document stores, internal APIs, approval steps, and user roles. AI only becomes valuable when it sits inside that chain without creating new friction.
For mid-sized teams, the bottleneck is often not the model. It is the integration surface. Which system triggers the workflow? Where is context assembled? Which API writes the result back? What happens if one dependency is down? Which user sees the answer, and in which screen?
That is why we often advise teams to strengthen the integration layer before they chase broader AI ambitions. If your core systems are brittle, AI will inherit that brittleness. Our earlier piece on building the AI integration roadmap for mid-sized businesses is relevant here, especially for sequencing architecture and delivery decisions. The same is true for the case we make in why an API layer often comes before a full legacy rewrite. You do not need to modernise everything at once, but you do need a stable way for AI to read, write, and trigger business actions.
What to fix first: map the full production workflow, including trigger systems, context assembly, write-back points, permissions, and failure states. If the integration path is unclear, the pilot is not production-ready.
4. There is no fallback path when the AI is uncertain, wrong, or unavailable
A surprising number of pilots are evaluated as if they must either work perfectly or be abandoned. That is not how good production systems behave.
In production, fallback design matters as much as primary-path performance. If the AI cannot classify a request confidently, what happens next? If a document cannot be parsed, does it go to a queue? If the model times out, does the process retry, hand off to a person, or revert to rules? If an output looks risky, who reviews it?
Without those answers, rollout teams hesitate for good reason. They can see the value, but they cannot trust the failure mode.
Fallback design is especially important for customer-facing and operations-heavy workflows because service does not pause just because an AI step is uncertain. The business still needs continuity.
This is also where many teams discover that the right target is not “full automation” on day one. It is controlled augmentation with clear exception handling.
What to fix first: define confidence thresholds, human review paths, retry rules, manual workarounds, and rollback conditions before launch.
If your pilot is stuck here, the right next step is usually a Request AI Readiness Assessment conversation, not another round of demo improvements.
5. Monitoring starts too late and measures the wrong things
Traditional software monitoring is not enough for AI-enabled workflows.
Uptime, response time, and error logs still matter. But they will not tell you whether the AI is degrading the business process. You also need visibility into input quality, output consistency, override rates, escalation rates, fallback frequency, latency by workflow step, and downstream business impact.
This is where production teams get caught out. The pilot team might report that the system is “running,” while operations can see that staff are manually correcting outputs all day, or that low-quality inputs are creating hidden rework.
Google’s MLOps guidance is helpful again because it frames monitoring around the full lifecycle, including data changes, retraining triggers, and validation gates. Microsoft’s Cloud Adoption Framework also pushes a wider operating model: governance, management, and security need to be planned as part of adoption, not patched in after rollout.
The commercial lesson is straightforward. If you cannot observe quality, cost, and failure patterns in production, you cannot improve the system with confidence.
What to fix first: decide which production metrics matter before launch, who receives alerts, how often outputs are reviewed, and what thresholds trigger intervention.
6. Security, privacy, and policy controls are still informal
Many teams tell themselves they will harden controls after the pilot proves value. That sounds practical, but it usually becomes the reason rollout stalls.
The moment AI touches customer records, pricing logic, internal documents, regulated workflows, or employee data, informal controls stop being acceptable. Security and compliance teams need answers: what data leaves the environment, which vendors are involved, what logs are stored, who can access prompts and outputs, what retention rules apply, and how sensitive content is filtered or masked.
This is not just a legal concern. It is an operational trust concern. Leaders will not expand usage if they cannot explain the control model to customers, regulators, or their own internal stakeholders.
The NIST framework and Microsoft’s AI adoption guidance both support the same principle here: responsible AI has to be translated into practical controls, checkpoints, and accountability. In other words, values are not enough. Teams need enforceable operating rules.
What to fix first: document data handling, access control, model/vendor boundaries, logging policy, and incident response before approving broader rollout.
7. The team has a pilot, but not a production operating model
This is the final gap, and it is the one that often wastes the most time.
A pilot can be carried by a few motivated people. Production cannot.
Once the system goes live, someone has to manage prompt and policy changes, approve workflow updates, review escalations, retrain or retune when inputs change, monitor usage, manage vendor costs, and answer for business results. If that model is not designed early, the pilot becomes an orphan.
Mid-sized companies are especially exposed here because they do not usually have spare specialist teams sitting on the bench. They need a practical operating model that fits the team they actually have.
That may mean centralising some decisions, limiting early rollout to one business unit, or choosing use cases with simpler exception patterns first. It may also mean using a phased implementation plan rather than pushing for company-wide deployment too soon.
What to fix first: define the run team, change process, support model, cost ownership, and rollout stages before calling the pilot “ready.”
What mid-sized teams should do next
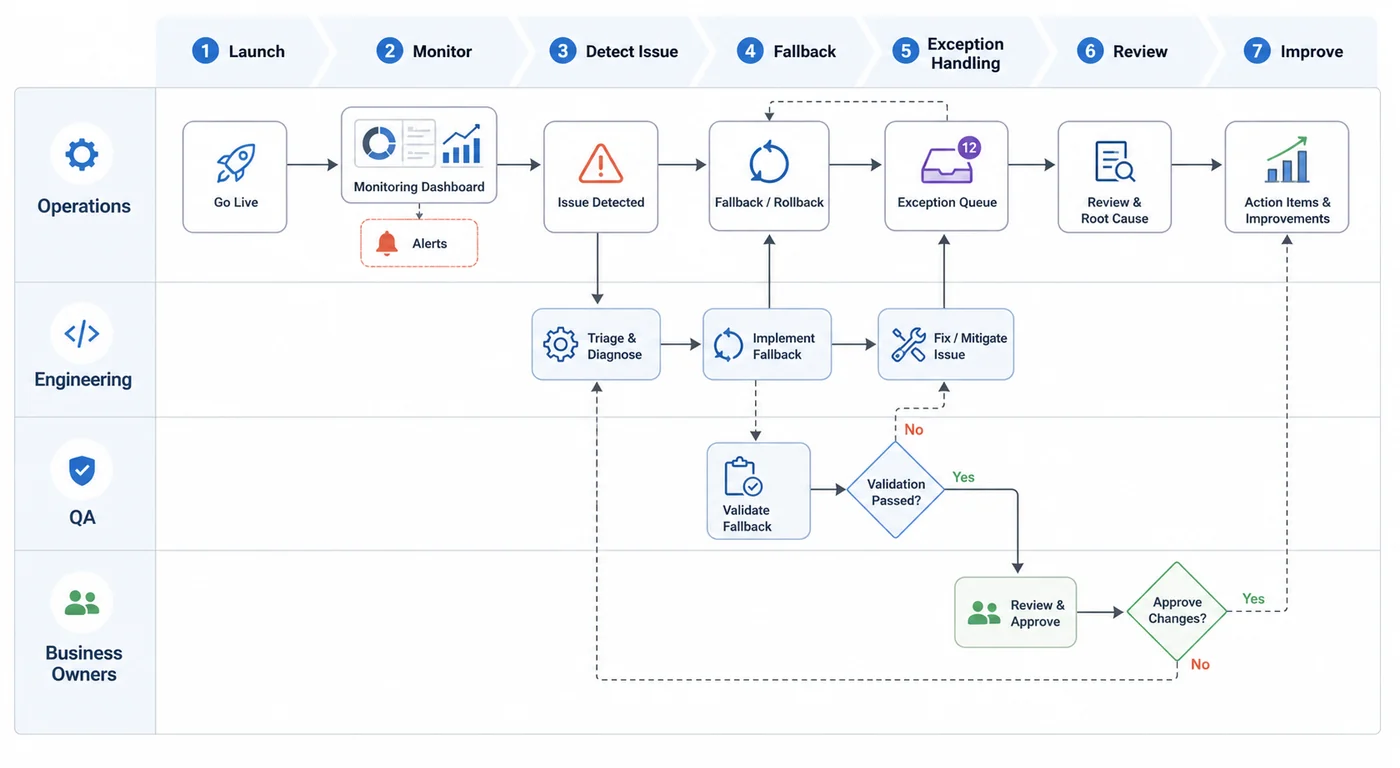
If you recognise these gaps, the answer is not to slow AI down forever. The answer is to treat readiness as part of delivery.
A sensible next step usually looks like this:
- Confirm the business outcome and owner.
- Map the live workflow, not just the model interaction.
- Review data quality and integration dependencies.
- Design fallback, approval, and exception paths.
- Set monitoring, security, and operating controls.
- Roll out in phases with measurable success criteria.
For many teams, the fastest route is not a dramatic rebuild. It is a scoped production-readiness plan that strengthens the workflow around the AI so the business can trust it.
Final thought
The market is full of AI pilots that looked impressive in a controlled setting and then went nowhere. That does not mean the opportunity was false. It usually means the surrounding system was underdesigned.
Mid-sized businesses win when they stop asking, “Can the model do this?” and start asking, “Which readiness gap is actually blocking launch?” That is the real threshold between experimentation and production.
If your team is at that threshold, the next conversation should be practical. Talk to an AI Architect if you need help diagnosing the workflow, integrations, controls, and rollout path. If you are earlier in the decision cycle, Request AI Readiness Assessment to identify what has to change before more budget goes into the pilot.
Sources
- NIST AI Risk Management Framework
- Google Cloud Architecture Center, MLOps continuous delivery and automation pipelines in machine learning
- Microsoft Cloud Adoption Framework, Create your AI strategy
FAQ
Why do AI pilots fail after a promising demo?
Because the demo proves a use case, not the operating system around it. Teams often discover too late that the data, APIs, approvals, fallback paths, monitoring, and ownership model are not strong enough for daily production use.
What is the biggest production risk for mid-sized teams adopting AI?
The biggest risk is usually not model quality. It is the gap between the pilot and the live business workflow, especially where AI has to connect with legacy systems, human reviewers, compliance rules, and service-level expectations.
How do you know if an AI use case is ready for production?
A use case is closer to production when the team can show clear ownership, stable data inputs, integration paths, measurable success criteria, fallback rules, monitoring, and a post-launch operating model.
Should we rebuild our systems before adding AI?
Not always. Many mid-sized teams move faster by improving the API and integration layer first instead of waiting for a full rewrite. The right choice depends on workflow complexity, data quality, and how much operational risk the current stack creates.
What should be monitored after launch?
Monitor more than uptime. Track input quality, output quality, handoff failures, fallback rates, latency, usage patterns, human override frequency, and any drift between expected and actual business outcomes.
What is the best first step if our pilot is stuck?
Run a readiness assessment before expanding the pilot. That helps you identify which gaps are technical, which are operational, and which need leadership decisions before more budget is spent.